Building on Previous Insights: Recap from Our Previous Post
In our previous post on the Statistics Foundations series, we highlighted the potency of statistics as a valuable tool for further understanding issues of interest through data. To do so, we would ideally want to study the whole population, which represents the complete collection of entities affected by the issue under investigation. However, in most cases, obtaining data for every entity within this population is simply unfeasible due to constraints such as cost and logistics or even impossible. Consequently, we employ a strategy of working with samples—subsets of this population that are randomly selected in a manner ensuring that every entity has an equal probability of being selected.
These samples, though more manageable in size, serve as our window into the broader population, enabling us to draw conclusions and glean insights about the population—a process known as inference. However, it’s important to acknowledge that working with samples introduces a critical challenge: the inherent limitations stemming from their smaller size in comparison to the population. As a consequence, we inevitably encounter errors in our analyses.
The essence of these errors lies in the inability of small samples to capture all the intricate nuances present within the population. While we can gain valuable insights and broad trends from our samples, the finer details and subtle variations within the population often elude our grasp. Thus, we find ourselves contending with sampling errors that can influence the accuracy of our conclusions.
Examining Sampling Errors in Data Summarization: The Case of the Mean
At the core of statistical analysis lies the foundational task of data summarization—a process that condenses data into a concise and understandable format. This fundamental procedure yields a clear and easily comprehensible overview of the data, facilitating a straightforward grasp of its essential characteristics.
Among these essential characteristics, two prominently stand out: central tendency and variability. Central tendency relates to the value around which the different data points cluster around. Conversely, variability quantifies the extent to which data points deviate from this central point, providing insights into the dispersion or spread of data relative to its central location. For instance, the mean serves as an example of a central tendency measure, while the standard deviation exemplifies a variability measure.
To visually illustrate the impact of sampling error, we will once again utilize the Kaggle dataset used in our previous post. This dataset contains information on 2,000 supermarket customers, including their age, annual income, and education level. For the purposes of this analysis, we will assume that this dataset represents our entire customer population.
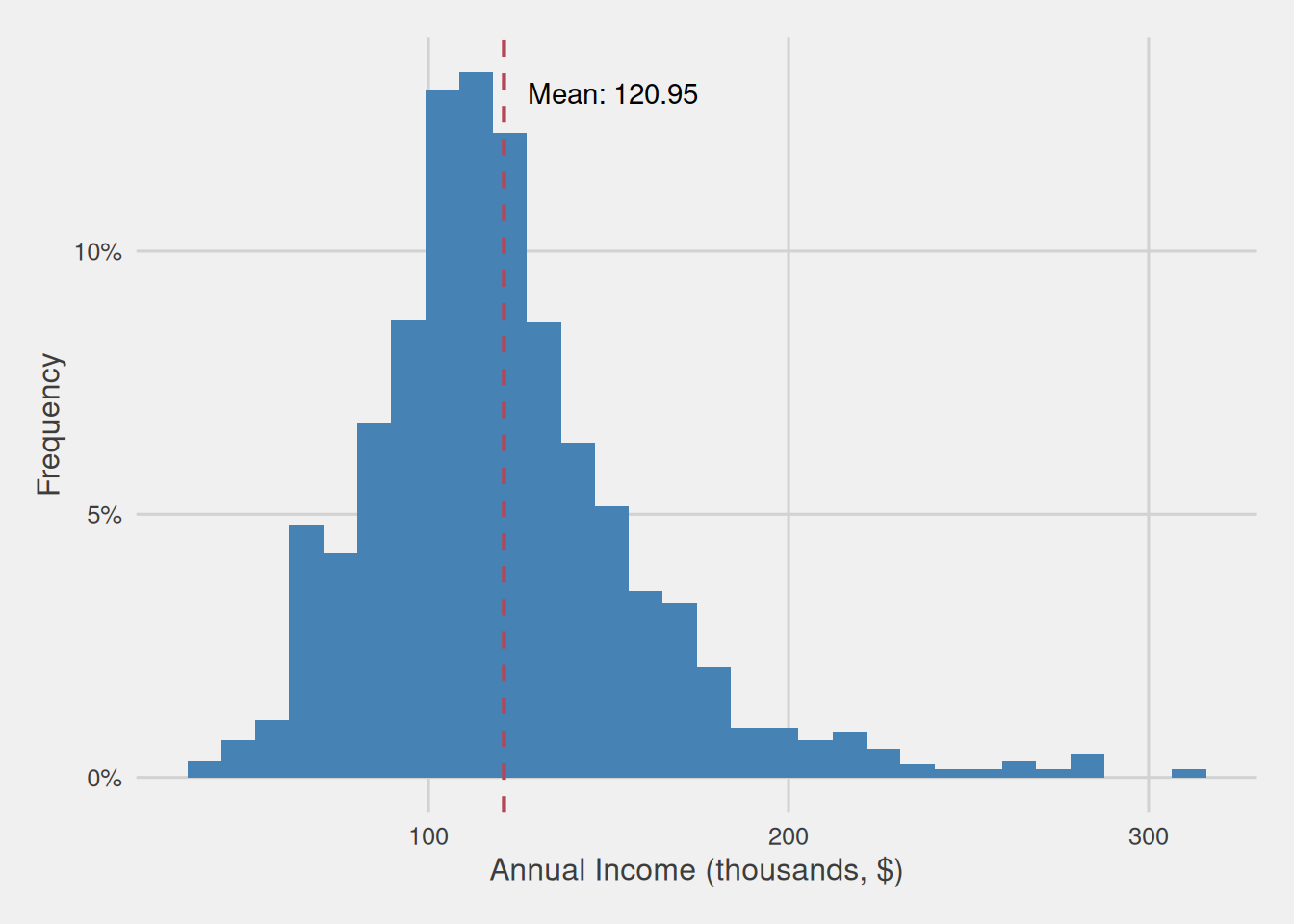
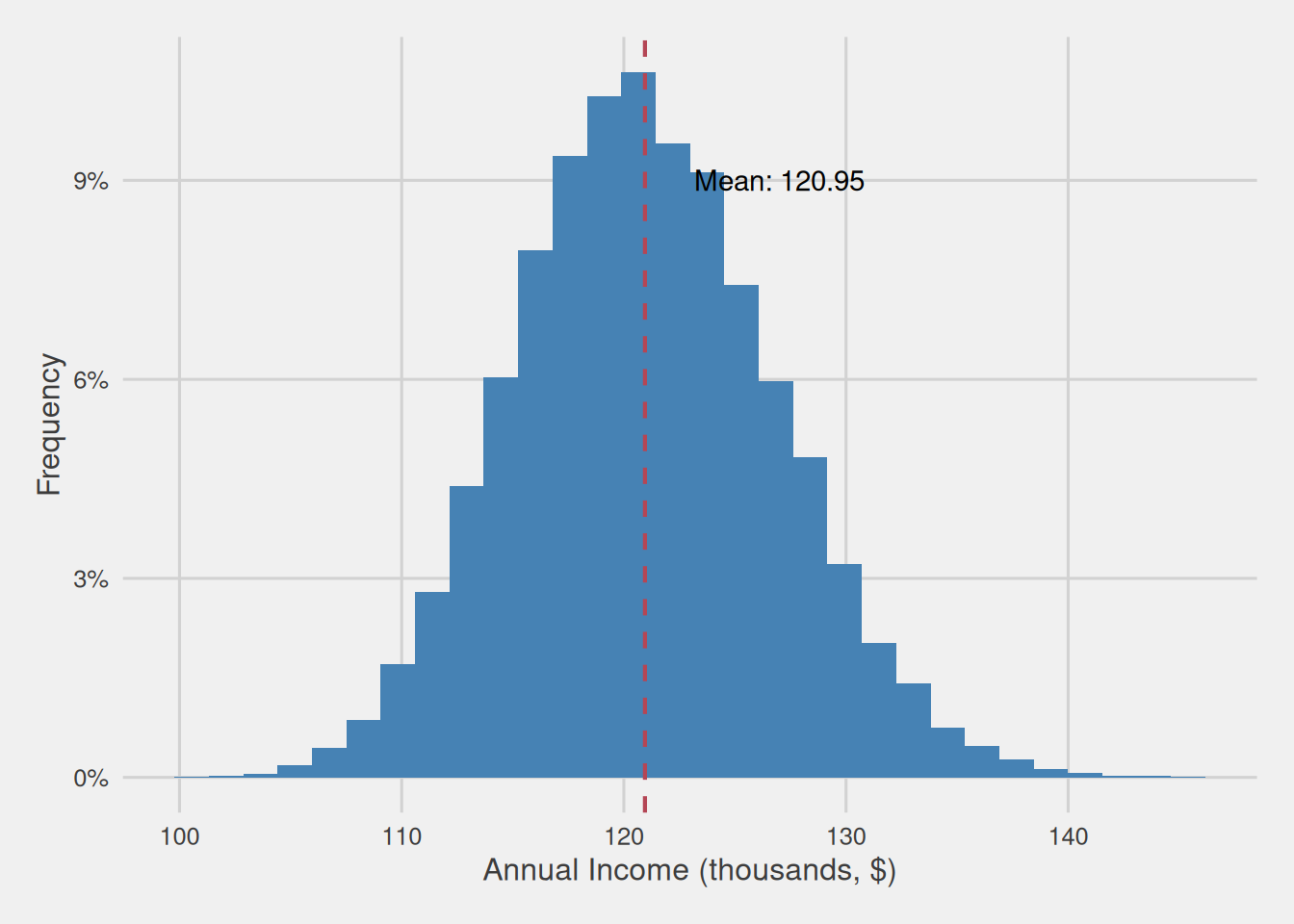
Let’s envision a scenario: our objective is to rapidly glean insights into the annual income of our customers. One straightforward strategy to achieve this is by computing the mean income, which furnishes us with a succinct metric representing the central tendency around which the majority of our customers’ annual incomes gravitate. In this endeavor, we observe that the mean annual income stands at a noteworthy $120,950, serving as a prominent reference point around which the annual incomes of our customers tend to concentrate.
Figure 1: Customer annual income distribution (thousands, $)
Sampling 40 customers and calculating their annual income mean
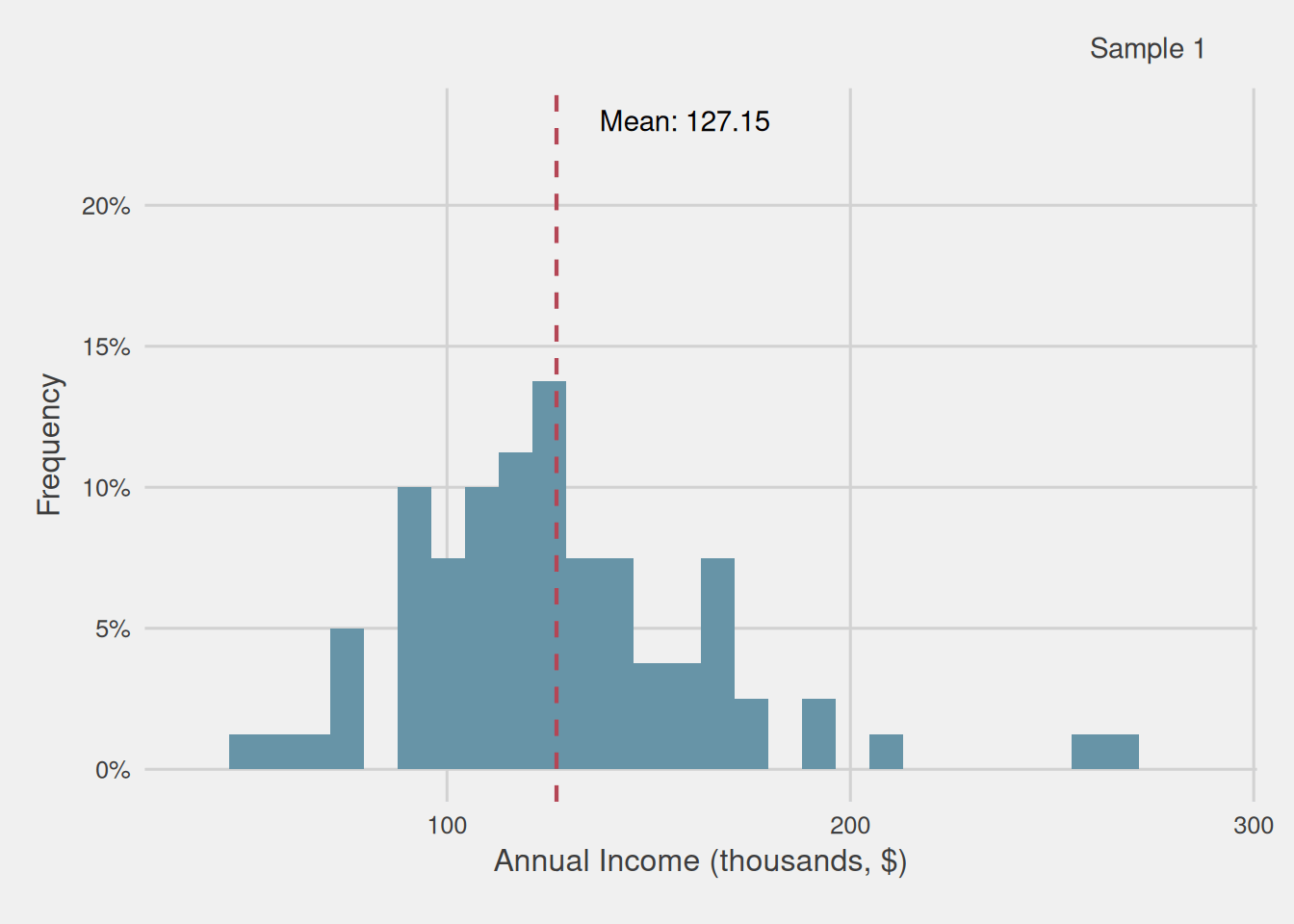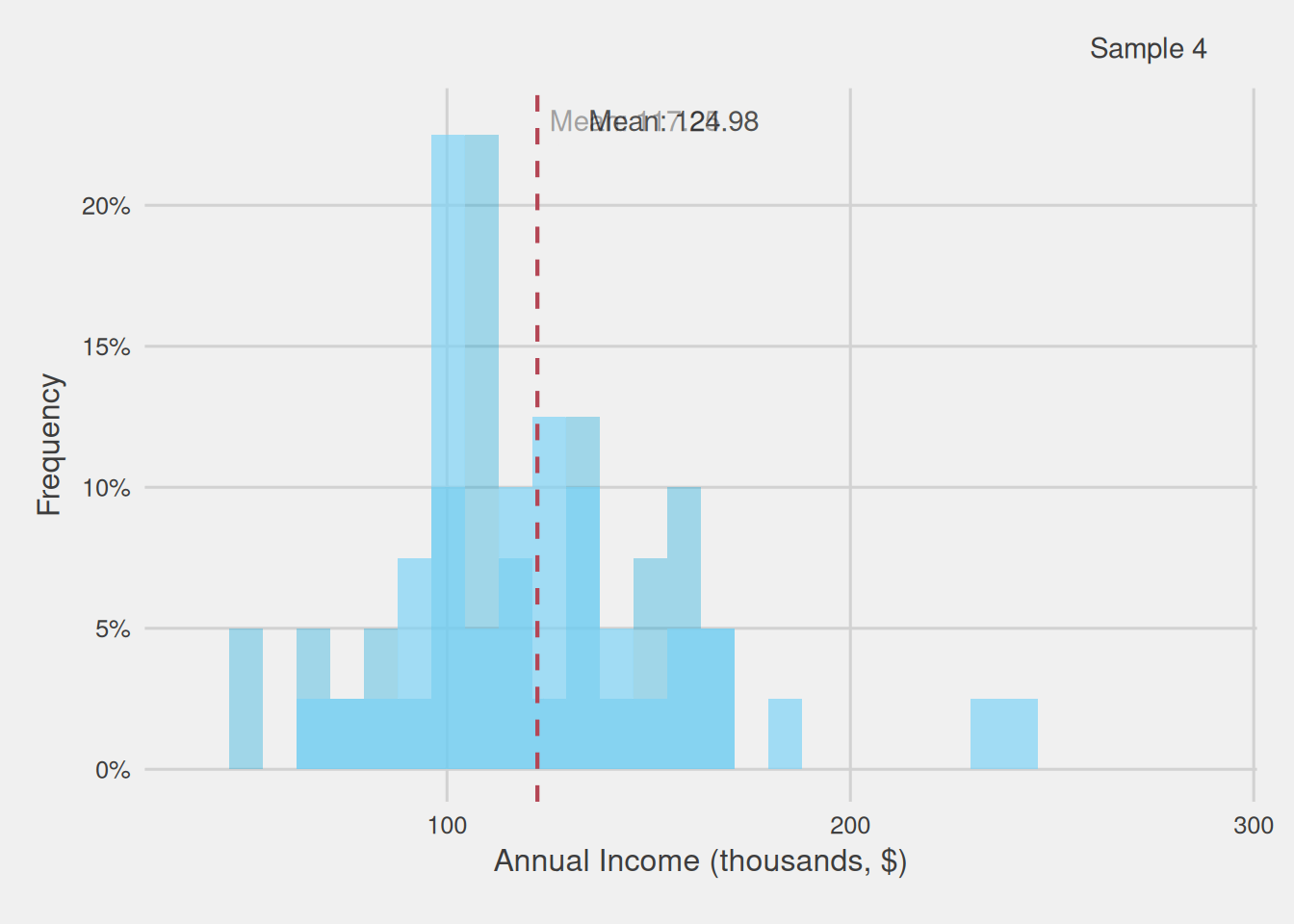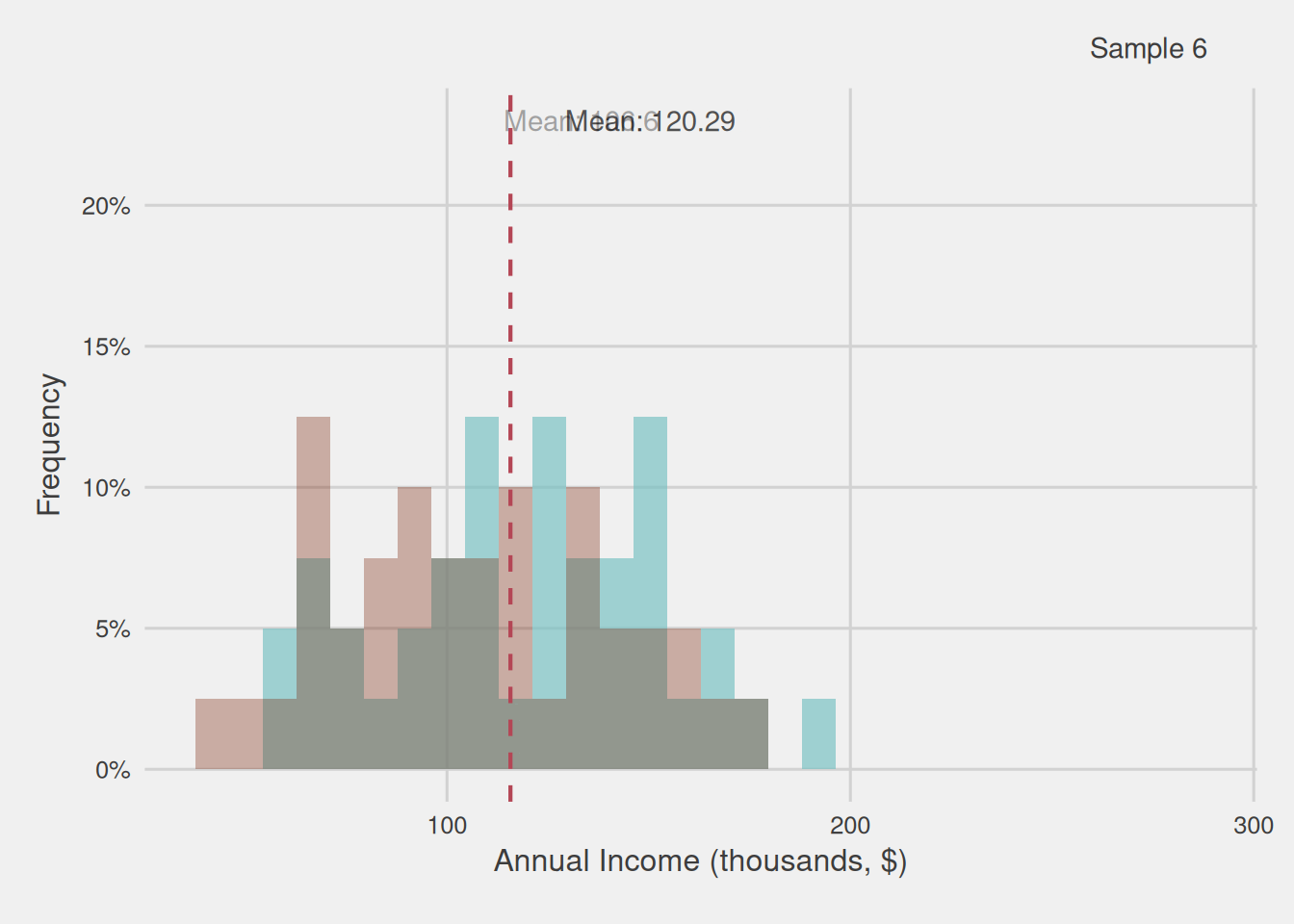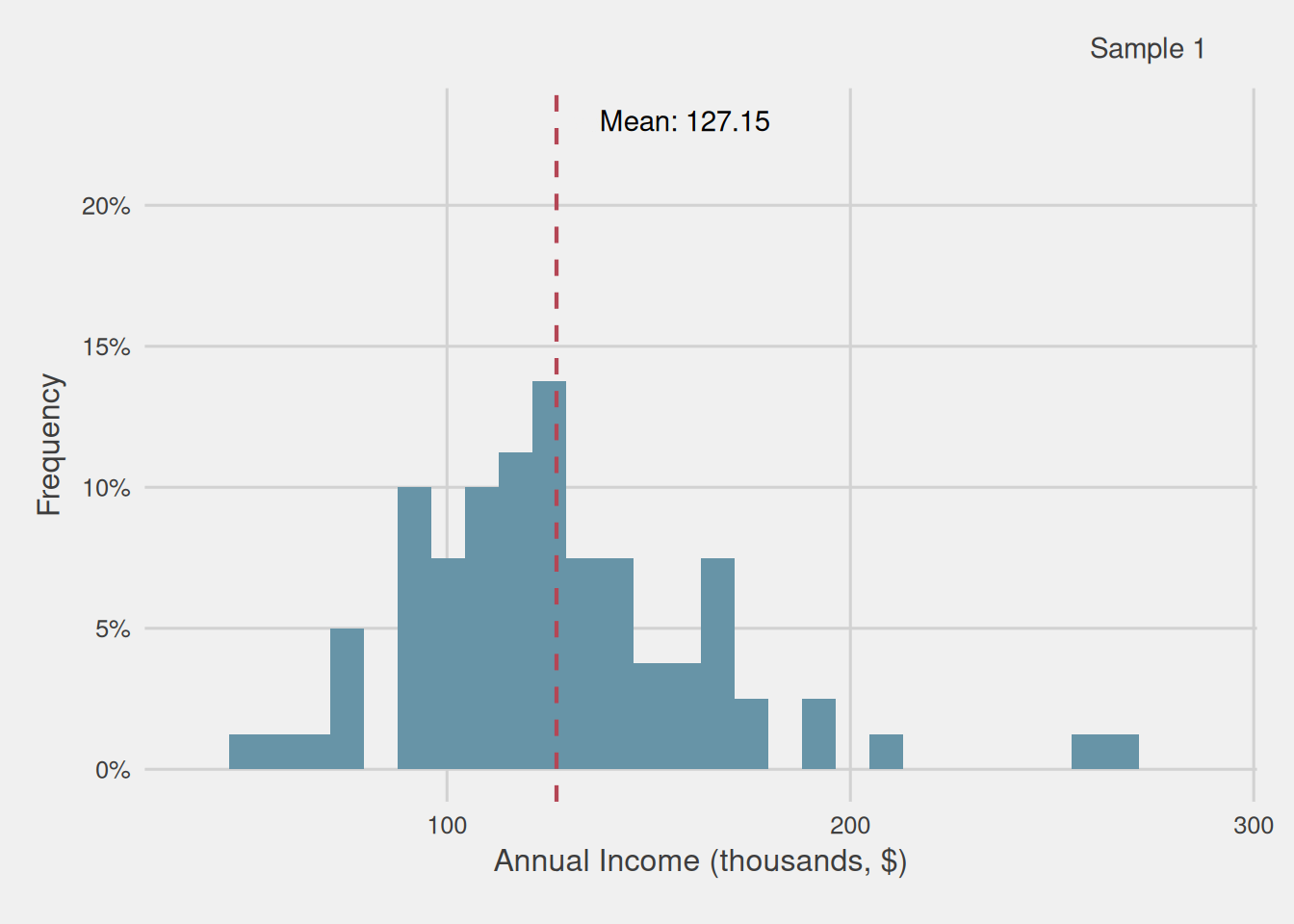
In this hypothetical case, we possess information about the sample. Consequently, we can obtain information about our population without any error by directly observing it. Therefore, now we know that our population has an average annual income of $120,950. However, in real-life scenarios, and as previously said, obtaining data for the whole population may be unfeasible or even not possible. For this reason, we will assume that we extract a random sample of 40 customers and compute the mean annual income from this sample.
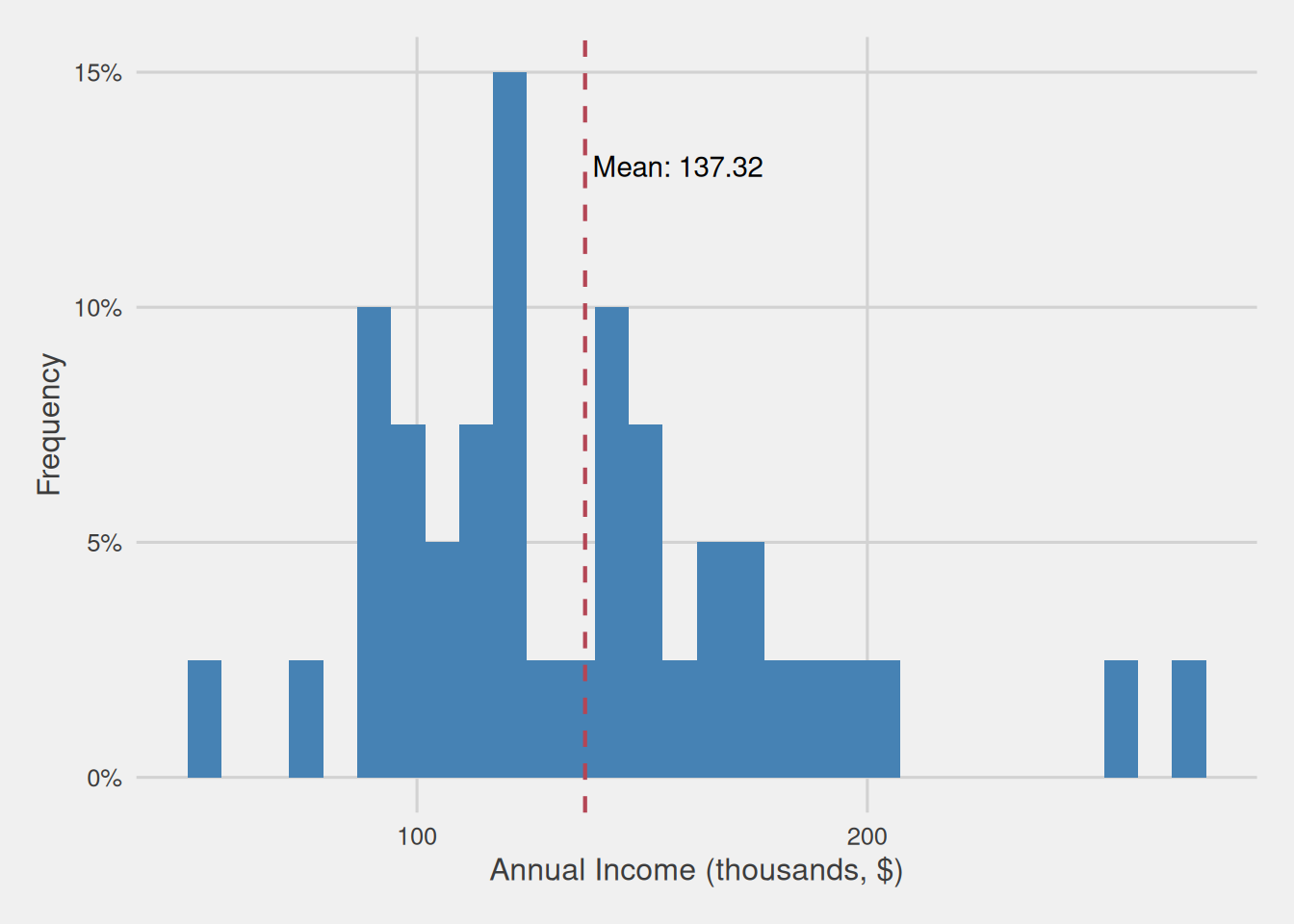
Figure 2: Customer annual income distribution for our sample with 40 observations (thousands, $)
As observed, in Figure 2, the mean value within this sample diverges from that of the broader population. Specifically, the mean for this sample stands at $137,320, contrasting with the population mean of $120,950. This difference amounts to $16,370, and it encapsulates what we commonly refer to as “error.” Notably, in this instance, we possess knowledge about the population, allowing us to discern this difference.
For this reason, the terminology we use to describe the metrics summarizing the data characteristics varies depending on whether they are computed within the population or a sample. In the former case, they are referred to as parameters, whereas in the latter, they are known as statistics. In statistical notation, parameters are typically denoted by Greek letters, such as \(\sigma\) for the standard deviation or \(\mu\) for the mean, while statistics are denoted by Latin letters, such as \(m\) for the mean and \(s\) for the standard deviation.
Randomness and sampling: Extracting several means of 40 observations
Moreover, it’s crucial to note that this sample was derived through a process of random selection. In other words, we randomly picked 40 customers from our population, ensuring that each customer had an equal likelihood of being included. This randomness implies that if we were to generate another sample of 40 customers, it would be improbable for this new sample to mirror the exact composition of the previous one or yield the same mean.
Figure 3 illustrates the annual income distribution of various samples, each consisting of 40 customers randomly selected from our initial population (including the sample we previously examined). It becomes evident that the distribution undergoes fluctuations across these diverse samples. Consequently, this variability gives rise to a spectrum of computed means, ranging from as low as $106,600 to as high as $137,320.
Figure 3: Customer annual income distribution for different samples of 40 customers (thousands, $)
Digging deeper: Exploring mean customer annual income with 10,000 different 40 samples
To deepen our comprehension of the variance in computed means, we embark on a more extensive analysis by replicating the previous procedure but on a much larger scale: generating precisely 10,000 samples, each composed of 40 individuals. For every one of these 10,000 samples, we compute the mean annual income. The resulting distribution of these 10,000 means, each originating from distinct samples of 40 individuals randomly selected from our complete population, is visually represented in Figure 4 through a histogram.
Figure 4: Average income distribution of 10,000 samples of 40 customers (thousands, $)
Figure 4 reveals significant insights. Notably, there is a substantial variation in the computed average annual incomes across the various samples, spanning an extensive spectrum from $100,684 to $145,543. This disparity translates into an error range spanning from -$20,266 to $24,593 in contrast with the population’s mean.
Nonetheless, an intriguing revelation emerges from this analysis. Despite the marked variability in sample means, the overall average of these mean annual incomes, drawn from distinct samples, precisely mirrors the population average. This observation means that the average incomes for the different samples consistently cluster around this point.
Moreover, it is worth noting that the distribution of annual income means extracted from these various samples adheres to a bell-shaped pattern, commonly known as a normal distribution. This pattern signifies that as we move farther away from the population average, the number of observations gradually diminishes.
Taken together, this implies that, in most instances, the mean annual income estimated from our sample tends to be closer rather than farther away from the population’s mean annual income. Nevertheless, it’s important to acknowledge that there are still situations where significant deviations from the sample mean can occur. The key concern here lies in the fact that if we lacked information about the population and solely possessed a sample with an annual income mean of $145,543, we might mistakenly conclude that, on average, our customers are wealthier than they actually are.
Increasing sample size and analyzing mean annual income distribution of 10,000 samples
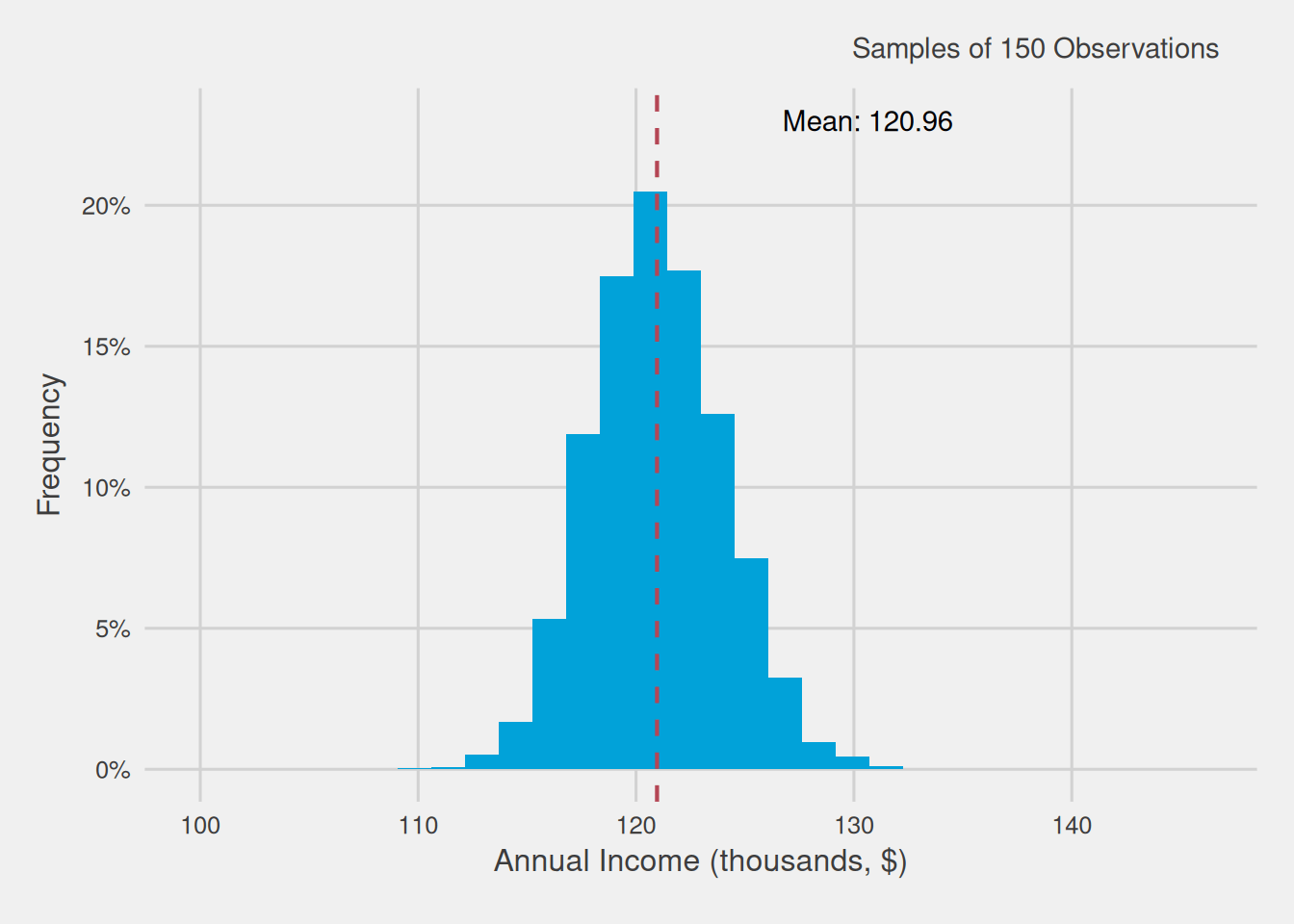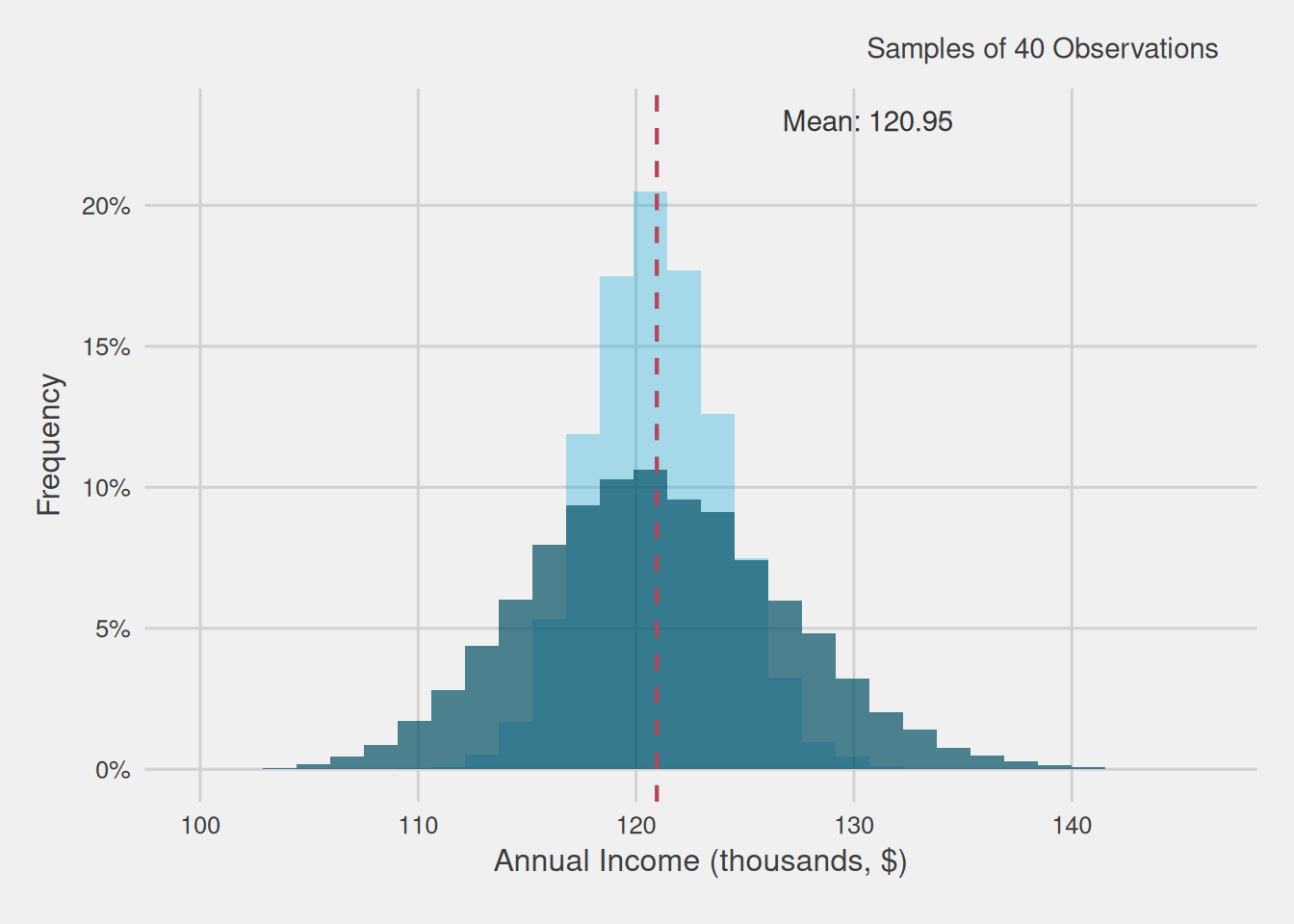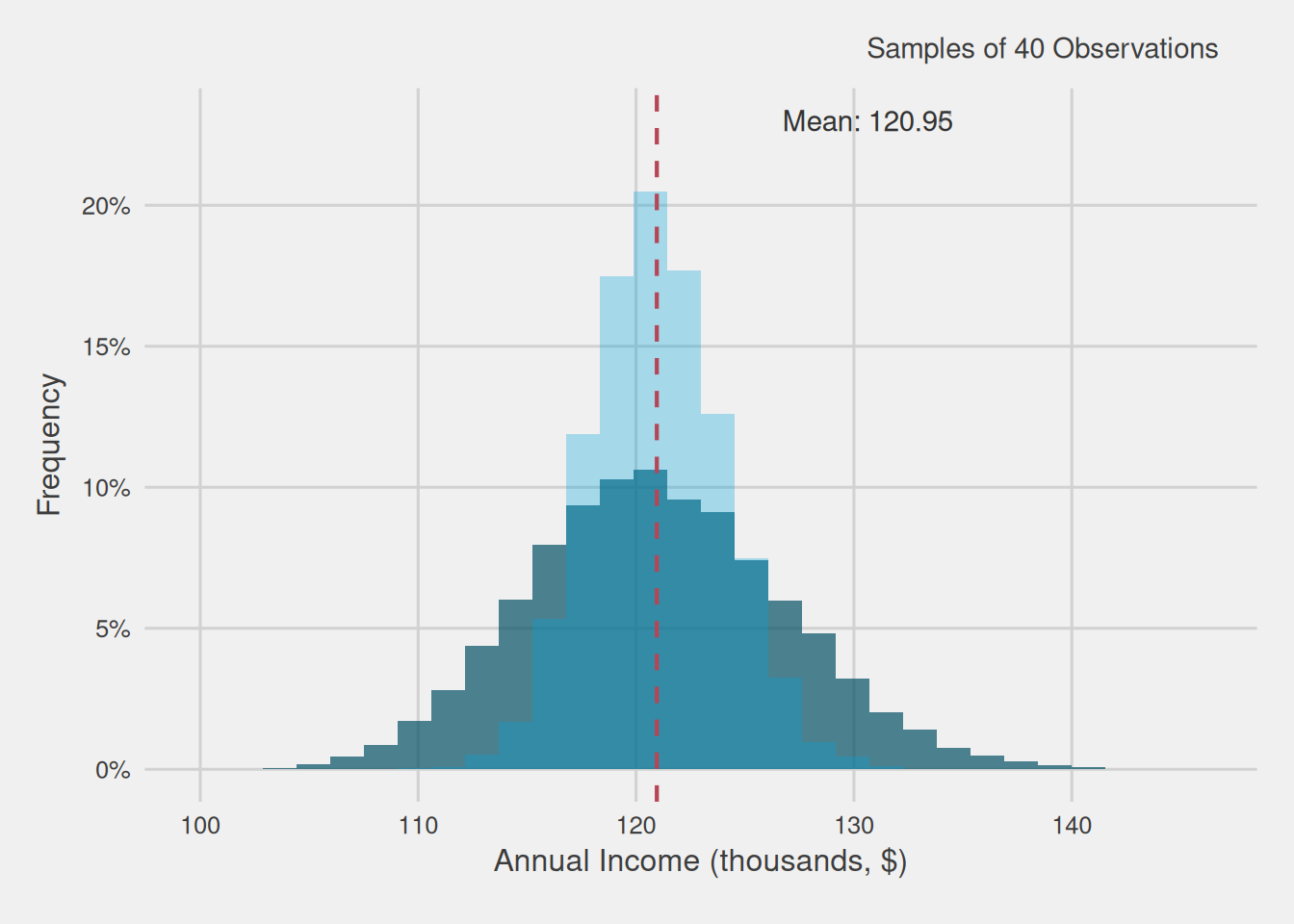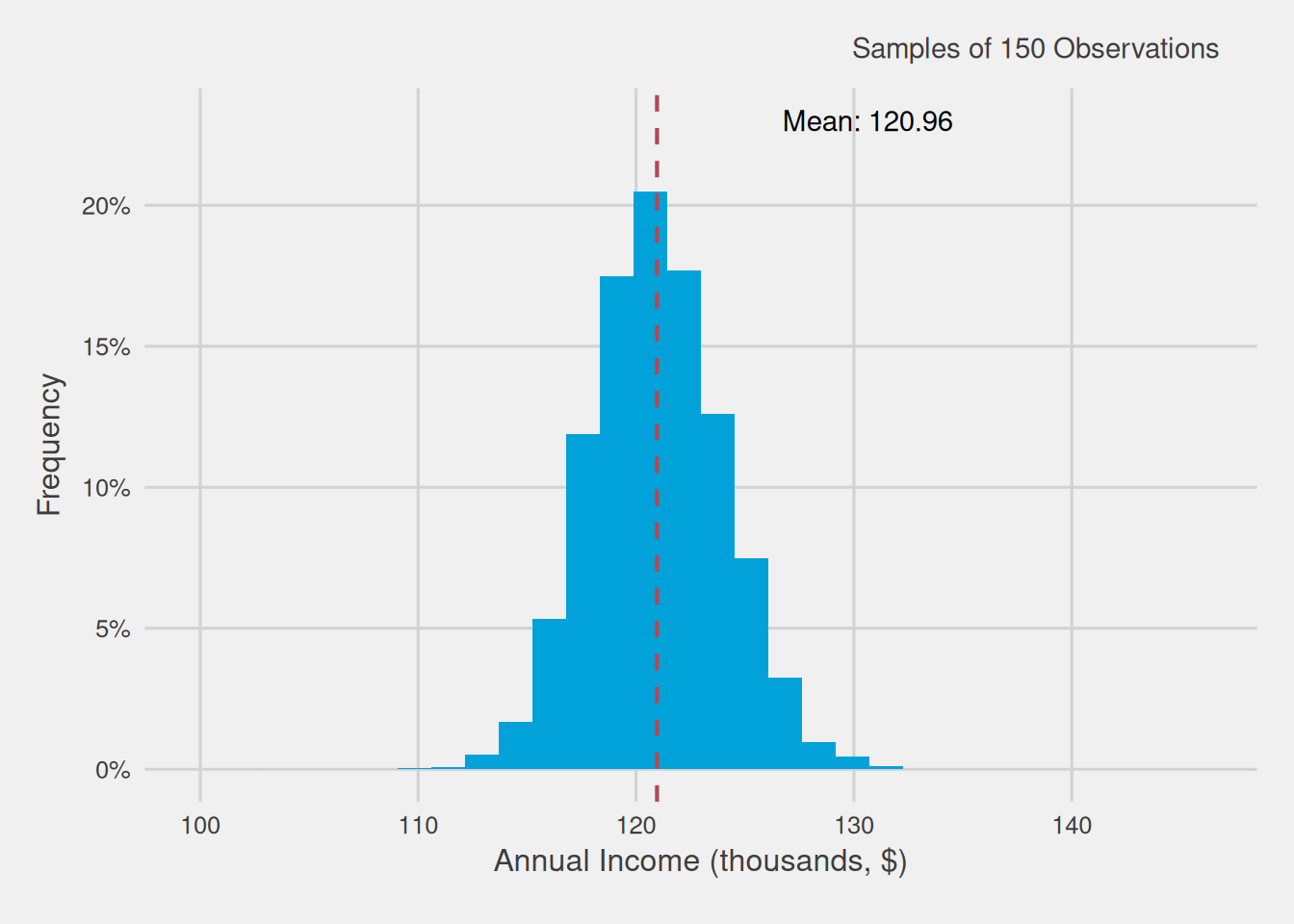
As previously mentioned, small samples encounter challenges in capturing the subtleties present within the population. Consequently, the larger the sample size, the more effectively we can apprehend these nuances. To illustrate this, we investigate how the variance of computed means changes when we collect samples of 150 customers, as opposed to the previous samples of 40 customers.
Once again, we generate 10,000 samples, each containing 150 customers, and calculate the mean annual income for each of these samples. Subsequently, we visualize the distribution of these mean annual incomes for these larger samples by creating a histogram.
Figure 5 provides a visual comparison between the distributions of means computed using 10,000 samples, each with 40 observations, and another set of samples, each comprising 150 observations.
Figure 5: Average income distribution of 10,000 samples of 40 customers vs 10,000 samples of 150 customers (thousands, $)
Figure 5 provides insights akin to those observed with 40 observations: the distribution of means exhibits a bell-shaped pattern, with the average closely approximating the population mean. However, a significant distinction emerges: the range within which sample means deviate from the overall mean, equivalent to the population average, is notably narrower. In essence, the variability is considerably reduced, indicating that the margin for error when using samples of 150 observations is substantially smaller than that with samples of 40.
Central Limit Theorem
In the previous examples, we’ve observed that when we calculate means from various samples, these means tend to follow a particular pattern – a bell-shaped distribution known as a normal distribution. This is not just a coincidence; it’s a fundamental concept in statistics called the Central Limit Theorem.
The Central Limit Theorem tells us that, regardless of the original shape of the data distribution, when we repeatedly draw samples of sufficient size from that data and calculate their means, those sample means will follow a normal distribution. This is a powerful idea because it allows us to make certain assumptions and conduct statistical analyses even when we don’t know the shape of the population’s distribution.
In this scenario, the distribution of means spans from $109,374 to $132,064, resulting in an error range of -$11,576 to $11,114 relative to the population mean. This range is significantly tighter compared to the error range obtained from samples of 40, where the deviation ranged from -$20,266 to $24,593.
Measuring the sampling error
Through the repetitive extraction of samples of consistent size from a given population, as demonstrated in our previous examples (with both 40 and 150-sized samples), we gain valuable insights into the potential magnitude of errors associated with samples of a particular size.
As we’ve witnessed, the average of multiple means calculated from samples of identical size closely aligns with, or is essentially identical to, the true mean of the population. Consequently, the spread or dispersion of these computed means from this point provides a measure of the magnitude of the sampling error. Put simply, the variability in the mean derived from multiple samples of equal size offers a quantifiable measure of the magnitude of the sampling error for samples of that particular size. This measure is commonly known as the standard error of the mean (which we will abbreviate as SEM).
Mathematically, we can express this as the standard error of the mean being equal to the standard deviation of the means of the different samples. Specifically, we prefer using the standard deviation rather than the variance because the former has the same units as the mean, while the latter has squared units. For instance, in the case of annual income, the units for variance would be in dollars squared (\(\$^2\)), while for the standard error, it’s just in dollars ($). In other words:
\[
\sqrt{Var(\bar{X})} = SEM
\]
This expression can be translated into the following form:
\[
\frac{\sigma}{\sqrt{n}} = SEM
\]
Here, \(σ\) represents the population standard deviation and \(n\) is the sample size. Establishing an inverse relationship between the standard error and the sample size: as the sample size increases, the standard error decreases. This principle aligns with our intuitive understanding, as seen in the previous post for the statistics foundations series, and as visually depicted in Figure 5.
Standard Error Derivation
Let’s recall that the mean of any variable is equal to the sum of the values of each observation of that variable divided by the total number of observations (which equals our sample size): \(\frac{1}{n}\sum_{i=1}^{n}X_i\). Therefore, we can rewrite the previous formula as follows:
We also know that the variance of a random variable multiplied by a constant “a” is equal to the variance of that variable multiplied by the square of that constant, i.e., \(Var(aR) = a^2Var(R)\), where \(a\) is a constant, and \(R\) is a random variable. This means that:
\[
\sqrt{\frac{1}{n^2}\text{Var}\left(\sum_{i=1}^{n}X_i\right)} = SEM
\]
Additionally, when dealing with a set of pairwise independent random variables (where the variability in one doesn’t depend on the others, as in our case), the variance of their sum is equal to the sum of their individual variances, i.e., \(\text{Var}[R_1 + R_2 + \cdots + R_n]\)\(=\)\(\text{Var}[R_1] + \text{Var}[R_2] + \cdots + \text{Var}[R_n]\), where \(R_1, R_2,…, R_n\) are pairwise independent random variables. This allows us to rewrite the formula for SEM as:
\[
\sqrt{\frac{1}{n^{2}}\sum_{i = 1}^{n}Var(X_i)} = SEM
\]
Let’s remember that our individual variables, denoted as \(X_i\), come from a population with variance equal to \(\sigma^2\). So, our formula becomes:
\[
\sqrt{\frac{1}{n^{2}}\sum_{i = 1}^{n}\sigma^2} = SEM
\]
Since we’re summing up \(n\) identical values, we can simplify further:
\[
\sqrt{\frac{1}{n^{2}}n\sigma^2} = SEM
\]
Ultimately, this can be further simplified to:
\[
\frac{\sigma}{\sqrt{n}} = SEM
\]
Applying these formulas, we can now calculate the Standard Error of the mean for sample sizes of 40 and 150. When we compute the standard deviation of the means obtained from multiple samples of 40 customers, we obtain a value of 5.86. Conversely, for samples of 150 customers, we obtained a value of 3.01, which is approximately two times smaller in terms of standard error.
Alternatively, we can utilize the formula that links the standard error to the population’s standard deviation and the sample size, represented as \(\frac{\sigma}{\sqrt{n}}\). Given our population’s standard deviation for annual income is 38.11, dividing this by \(\sqrt{40}\) yields a value of 6.03 for a sample size of 40, while dividing it by \(\sqrt{150}\) results in a value of 3.11 for a sample size of 150.
However, it’s important to note that there are disparities between the results obtained from these two approaches. This is because the first formula relies on a finite number of samples (10,000 in this case), and to obtain equivalent values, the number of samples would need to tend towards infinity, meaning a significantly larger amount of samples.
Estimating the standard error
Up until now, we have seen that we can compute the standard error of the mean by taking multiple samples of the same size from the population, calculating their means, and extracting the variability of such means.
Yet, let’s face it—in the real world, resources are finite, and repeatedly plucking samples from the population to estimate the standard error can be an extravagant expenditure of these precious assets. Instead, it’s often a more judicious allocation of resources to channel our efforts into amassing a larger sample. As we’ve come to appreciate, a larger sample which better captures the nuances of the population, decreasing the sampling error.
In addition to the aforementioned method, we’ve also explored an alternative approach for calculating the standard error—one that bypasses the need to repeatedly extract multiple samples from the population. This alternative method involves dividing the population’s standard deviation by the square root of the sample size (\(\frac{\sigma}{\sqrt{n}}\)). However, it’s essential to note that this formula hinges on having access to information about the entire population. This requirement underscores the very reason why we find ourselves seeking to compute the standard error in the first place—a challenge born out of the impracticality of obtaining data for the entire population, compelling us to work with samples and consequently introducing the sampling error.
Nonetheless, it’s crucial to remind ourselves that the core objective when working with a sample is to glean insights into the larger population and derive meaningful conclusions from it. Within this context, it’s reasonable to assume that the standard deviation we observe within our sample (\(s\)) can serve as a dependable proxy for the population’s standard deviation (\(\sigma\)). This assumption empowers us to substitute the population standard deviation in the traditional formula (\(\frac{\sigma}{\sqrt{n}}\)) with the sample standard deviation (\(s\)) derived from that very population:
\[
SE \approx \frac{s}{\sqrt{n}}
\]
By making this substitution, we arrive at an approximation for the standard error. It provides us with a measure of the potential error we may encounter when drawing conclusions from a sample, all without the need for complete information about the population.
A final note
Throughout this post, we’ve centered our attention on the standard error of the mean. Yet, it’s imperative to acknowledge that other statistics, such as variance and standard deviation, likewise harbor their own standard errors. Throughout this post, we’ve centered our attention on the standard error of the mean. Yet, it’s imperative to acknowledge that other statistics, such as variance and standard deviation, likewise harbor their own standard errors. When we compute these statistics from a sample, the values we obtain can deviate from those of the population, consequently introducing an element of error into our analyses.
However, it’s crucial to acknowledge that the formulas we’ve previously derived for calculating the standard error aren’t universally applicable to all statistics. These formulas have been derived with the mean as their reference point. Nevertheless, it’s worth noting that the fundamental concept behind deriving formulas for computing the standard error for other statistics remains consistent: It is based on the variability of a specific statistic obtained from various samples of the same size.
Summary
Sampling is necessary because obtaining data for the entire population is often impractical.
The use of samples introduces the challenge of sampling errors.
Sampling errors arise because small samples cannot capture all the nuances present in the population.
This leads to variations in common measures like the mean between the sample and the population.
To illustrate this, we simulated the extraction of 10,000 samples of the same size from our exemplary population and observed that:
The mean from different samples exhibits variability.
Despite this variability, the average of mean values from various samples tends to closely align with the population average.
A normal distribution pattern is evident in the distribution of annual income means from different samples, indicating that samples with means close to the population mean are more likely.
Larger sample sizes reduce the standard error and yield more accurate estimates, as they better capture the population’s intricacies.
When extracting multiple samples of the same size from a population and calculating their means, the average of these sample means corresponds to the population mean. This allows us to quantify the degree of error associated with that sample size by measuring their variability, i.e., how much they deviate from the population mean.
Standard error of the mean (SEM) is mathematically linked to the population’s standard deviation and sample size.
In practice, we estimate the SEM using our sample’s standard deviation.
Increasing the sample size results in a smaller standard error.
Standard error serves as a valuable tool for quantifying the precision of sample-based estimates and is essential for robust statistical analysis.
Click to reveal the R code used to generate the various plots in this post.
## Reading the "population" and visualizing itlibrary(gganimate)library(tidyverse)library(ggthemes)#Read customer datacustomer_data <-read.csv("assets/customer.csv")customer_data$Income <- customer_data$Income/1000#Compute the average and standard deviation of the incomeaverage_income <-mean(customer_data$Income)ggplot(customer_data, aes(x = Income)) +geom_histogram(aes(y =after_stat(count /sum(count)*100)), fill ="steelblue") +geom_vline(xintercept = average_income, color ="#B44655", linetype ="dashed", size =0.75) +labs(x ="Annual Income (thousands, $)",y ="Frequency" ) +theme_fivethirtyeight() +theme(plot.title =element_text(hjust =0),axis.title.x =element_text(hjust =0.5),axis.title.y =element_text(hjust =0.5),plot.caption =element_text(hjust =0)) +scale_y_continuous(labels = scales::percent_format(scale =1)) +annotate("text", x = average_income *1.25, y =13, label =paste0("Mean: ", round(average_income, 2))) ## Sampling 40 customers and calculating their annual income mean + visualizing their distributionset.seed(150)customer_data_sample <- customer_data[sample(nrow(customer_data), 40), ]#Compute the average and standard deviation of the incomeaverage_income <-mean(customer_data_sample$Income)ggplot(customer_data_sample, aes(x = Income)) +geom_histogram(aes(y =after_stat(count /sum(count) *100)), fill ="steelblue") +geom_vline(xintercept = average_income, color ="#B44655", linetype ="dashed", size =0.75) +labs(x ="Annual Income (thousands, $)",y ="Frequency" ) +theme_fivethirtyeight() +theme(plot.title =element_text(hjust =0),axis.title.x =element_text(hjust =0.5),axis.title.y =element_text(hjust =0.5),plot.caption =element_text(hjust =0)) +scale_y_continuous(labels = scales::percent_format(scale =1)) +annotate("text", x = average_income *1.15, y =13, label =paste0("Mean: ", round(average_income, 2))) ## Extracting several 40 customers and calculating their annual income mean + visualizing their distribution customer_data_samples <- customer_data_samplecustomer_data_samples$Average_Sample <-"Sample 1"seeds <-seq(300, 5500, length.out =8)i <-2for(seed in seeds) {set.seed(seed) customer_data_sample <- customer_data[sample(nrow(customer_data), 40),]row.names(customer_data_sample) <-NULL average_income <-round(mean(customer_data_sample$Income), 2) customer_data_sample$Average_Sample <-paste0("Sample ", i) customer_data_samples <-rbind(customer_data_samples, customer_data_sample) i <- i +1}data_income_average <- customer_data_samples %>%summarise(meanIncome =mean(Income), .by = Average_Sample)p <-ggplot(customer_data_samples, aes(x = Income, fill = Average_Sample)) +geom_histogram(aes(y =after_stat(density*width))) +geom_vline(data = data_income_average, aes(xintercept = meanIncome),color ="#B44655", linetype ="dashed", size =0.75) +geom_text(data = data_income_average, aes(x = meanIncome *1.25, y =0.23, label =paste0("Mean: ", round(meanIncome, 2)))) +labs(title ="Annual Income Distribution",x ="Annual Income (thousands, $)",y ="Frequency" ) +theme_fivethirtyeight() +scale_fill_economist() +scale_y_continuous(labels = scales::percent_format()) +theme(plot.title =element_text(hjust =0.95, size =11),axis.title.x =element_text(hjust =0.5),axis.title.y =element_text(hjust =0.5),plot.caption =element_text(hjust =0), legend.position="none") +transition_states(Average_Sample, transition_length =1.25, state_length =2) +enter_fade() +exit_fade() p <- p +labs(title ="{closest_state}")# Render the animationanim <-animate(p, nframes =180, duration =20)anim## Extracting 10,000 samples of 40 observations and calculate their mean + visualize the distribution of the meansset.seed(3)# Create an empty numeric vector of length 10000 named 'sample40_means'sample40_means <-numeric(length =10000)# Generate a for loop iterating 10000 times# For each iteration, the variable 'i' takes the value of the current iterationfor (i in1:10000) {# Generate a sample of 40 observations from the Income variable sample_population <-sample(customer_data$Income, 40)# Calculate the mean of the sample and store it in the 'i' position of the 'sample_means' vector sample40_means[i] <-mean(sample_population)}average_income <-round(mean(sample40_means), 2)sample_means <-data.frame(Income = sample40_means)ggplot(sample_means, aes(x = Income)) +geom_histogram(aes(y =after_stat(count /sum(count)*100)), fill ="steelblue") +geom_vline(xintercept = average_income, color ="#B44655", linetype ="dashed", size =0.75) +labs(x ="Annual Income (thousands, $)",y ="Frequency" ) +theme_fivethirtyeight() +theme(plot.title =element_text(hjust =0),axis.title.x =element_text(hjust =0.5),axis.title.y =element_text(hjust =0.5),plot.caption =element_text(hjust =0)) +scale_y_continuous(labels = scales::percent_format(scale =1)) +annotate("text", x = average_income *1.05, y =9, label =paste0("Mean: ", round(average_income, 2))) ## Extracting 10,000 samples of 150 observations and calculate their mean + visualize the distribution of the meansset.seed(1500)# Create an empty numeric vector of length 10000 named 'sample_means'sample_means <-numeric(length =10000)# Generate a for loop iterating 10000 times# For each iteration, the variable 'i' takes the value of the current iterationfor (i in1:10000) {# Generate a sample of 150 observations from the Income variable sample_population <-sample(customer_data$Income, 150)# Calculate the mean of the sample and store it in the 'i' position of the 'sample_means' vector sample_means[i] <-mean(sample_population)}average_income <-round(mean(sample_means), 2)sample_means_40 <-data.frame(Income = sample40_means)sample_means_40$Observations <-"Samples of 40 Observations"sample_means_150 <-data.frame(Income = sample_means)sample_means_150$Observations <-"Samples of 150 Observations"sample_means <-rbind(sample_means_40, sample_means_150)data_income_average <- sample_means %>%summarise(meanIncome =mean(Income), .by = Observations)p <-ggplot(sample_means, aes(x = Income, fill = Observations)) +geom_histogram(aes(y =after_stat(density*width))) +geom_vline(data = data_income_average, aes(xintercept = meanIncome),color ="#B44655", linetype ="dashed", size =0.75) +geom_text(data = data_income_average, aes(x = average_income *1.08, y =0.23, label =paste0("Mean: ", round(meanIncome, 2)))) +labs(title ="Annual Income Distribution",x ="Annual Income (thousands, $)",y ="Frequency" ) +theme_fivethirtyeight() +scale_fill_economist() +scale_y_continuous(labels = scales::percent_format()) +theme(plot.title =element_text(hjust =0.95, size =11),axis.title.x =element_text(hjust =0.5),axis.title.y =element_text(hjust =0.5),plot.caption =element_text(hjust =0), legend.position="none") +transition_states(Observations, transition_length =1.25, state_length =2) +enter_fade() +exit_fade() p <- p +labs(title ="{closest_state}")# Render the animationanim <-animate(p, nframes =180, duration =10)anim